DreamFace vs Seedance 2.0
Side-by-side comparison to help you choose the right AI tool.
Create jaw-dropping avatar videos with lifelike voices in 19 languages, all with one click using DreamFace!.
Last updated: February 28, 2026
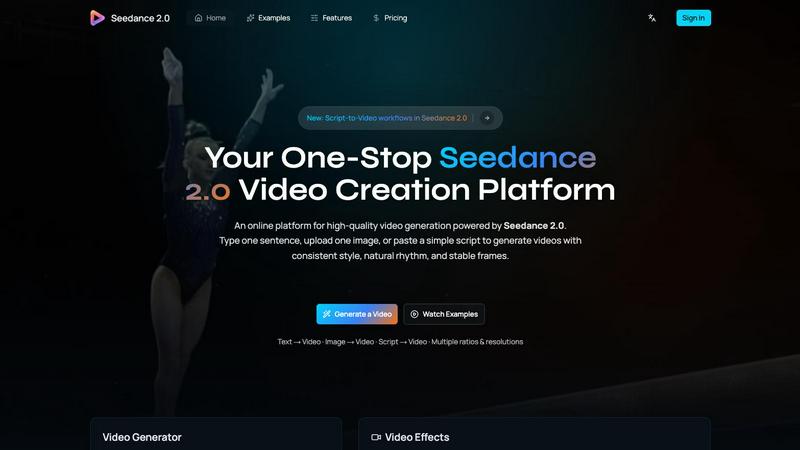
Seedance 2.0
Generate high-quality videos from text or images. Consistent style, natural motion, and stable frames guaranteed.
Visual Comparison
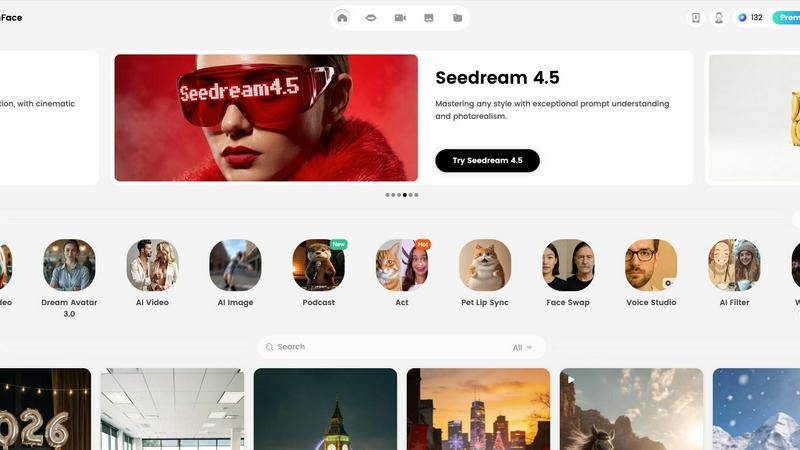
DreamFace
Seedance 2.0
Overview
About DreamFace
DreamFace is the next-gen AI-powered content creation platform that's totally changing the game for creators everywhere. With over 20 million users and 200,000+ paid subscribers, it's a hot favorite among marketers, business owners, and anyone who wants to make eye-popping content without breaking a sweat. Imagine cranking out stunning avatar videos, engaging AI videos, and jaw-dropping images with just a few clicks! No need for fancy gear or a film crew—DreamFace makes it super easy to unleash your creativity. With cutting-edge tools like background removal and photo enhancement, you can create pro-level multimedia content in minutes. Whether you're crafting social media posts, marketing materials, or just having fun, DreamFace is your go-to solution for making ideas come alive. This platform is all about accessibility and fun, ensuring that everyone, regardless of their tech skills, can join in on the content creation revolution.
About Seedance 2.0
Seedance 2.0 is the latest AI video generation model developed by ByteDance's Seed research team. Building on the original Seedance, it delivers major improvements in motion coherence, physical realism, and multimodal generation capability.
Key Features
• Text-to-Video: Turn a single sentence into a complete cinematic scene with coherent motion
• Image-to-Video: Use reference images to guide composition, identity, and visual style
• Integrated Audio Generation: The Pro version generates synchronized video and audio in a single pass, including sound effects, background music, speech synthesis, and multilingual lip-sync
Technical Architecture
Seedance 2.0 uses a novel diffusion transformer architecture designed for temporal consistency between video frames. Unlike models that treat each frame independently, Seedance 2.0's temporal attention mechanism:
• Reuses motion cues across frames
• Preserves character identity and proportions
• Maintains consistent lighting and geometry
• Produces fewer flickers and smoother transitions
Physics-Aware Motion
Seedance 2.0 excels at understanding physical dynamics:
• Cloth fluttering in the wind
• Water splash physics
• Realistic flames and smoke
• Complex particle effects