CloudBurn vs OpenMark AI
Side-by-side comparison to help you choose the right AI tool.
CloudBurn
Stop AWS bill shock by seeing your cloud costs right in your pull requests.
Last updated: February 28, 2026
Stop guessing which AI model slaps for your task, just describe it and we'll benchmark 100+ models for you in minutes, no API keys needed.
Last updated: March 26, 2026
Visual Comparison
CloudBurn
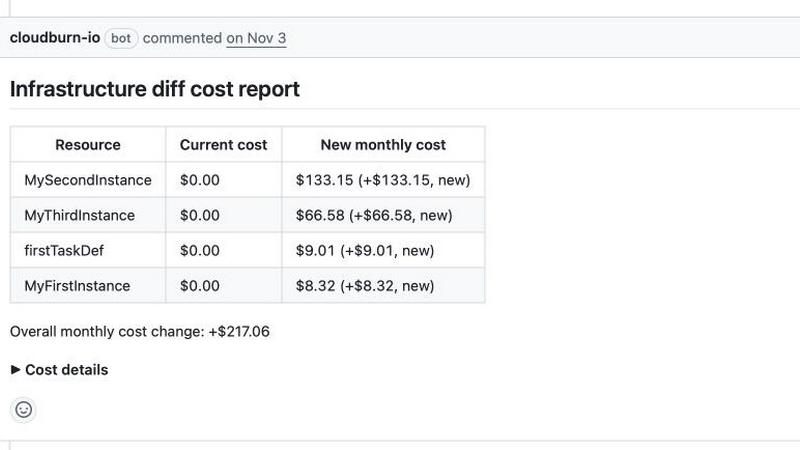
OpenMark AI

Feature Comparison
CloudBurn
Real-Time PR Cost Commentary
Forget waiting for the monthly invoice to get roasted. CloudBurn's bot jumps into your GitHub pull requests the second there's a diff, automatically posting a detailed cost breakdown. It shows you exactly what's new, what's changed, and—most importantly—how much it's gonna cost you per month. It's like having a super-smart, cloud-pricing-obsessed teammate commenting on every PR, keeping everyone honest before the merge button is even clicked.
Terraform & AWS CDK Native Integration
CloudBurn doesn't ask you to learn some new funky syntax or overhaul your entire process. It works with the tools you're already using. Just hook up the provided GitHub Action for your Terraform plan or AWS CDK diff output, and you're golden. It speaks the language of infrastructure-as-code, so you get accurate estimates based on your actual configs, not just guesses.
Automatic & Always-Up-to-Date Pricing
Manually looking up AWS prices is a snooze-fest and outdated almost immediately. CloudBurn's engine is wired directly into the latest AWS pricing data. Whether it's On-Demand instances, Fargate tasks, or funky new services, the cost estimates are based on real, current prices for your specific region. No more nasty surprises because you used last year's spreadsheet.
Catch Catastrophic Misconfigs Early
This is the big one. CloudBurn is your early warning system for those "oh-crap" moments. That accidentally-provisioned x1e.32xlarge instance? The S3 bucket set to replicate globally? CloudBurn will flag it with a giant dollar sign in your PR, giving you a chance to say "whoa, NOPE" and fix it before it costs you a down payment on a car. It turns costly blunders into minor code corrections.
OpenMark AI
Plain Language Task Wizard
Forget writing complex code or JSON configs. You just type out what you want the AI to do, like "extract the invoice total and due date from this messy email" or "write a chill marketing tweet for this new feature." OpenMark's wizard takes your vibe and builds the benchmark. It's the ultimate "explain it to me like I'm five" but for setting up professional-grade LLM tests. No PhD in prompt engineering required.
Real API Cost & Latency Showdown
This ain't about theoretical token prices on a spec sheet. OpenMark makes real API calls to every model and shows you the actual receipt—how much that specific request cost and how long it actually took to come back. You can instantly spot the models that give you 95% of the quality for 50% of the price, or the ones that are weirdly slow. It's all about cost efficiency, not just raw cheapness.
Variance & Consistency Scoring
Any model can have a one-hit-wonder output. OpenMark runs your task multiple times for each model to see the variance. You get to see if Model A nails it 9 times out of 10, or if Model B is a complete wildcard that gives you genius one minute and gibberish the next. This stability check is crucial for shipping something you can actually trust in production, not just a cool demo.
Hosted Benchmarking (No Key Drama)
The biggest flex? You don't need to set up individual API keys for OpenAI, Anthropic, Google, etc., just to compare them. You buy OpenMark credits and it handles all the backend API calls across its massive model catalog. It removes the setup hell and lets you focus purely on the results. It's like having a universal remote for every AI model out there.
Use Cases
CloudBurn
The "Oops, I Built a Gold-Plated Dev Environment"
Every dev has done it: spun up a beastly instance "just for testing" and forgotten about it. With CloudBurn, when a dev opens a PR to add a c5n.18xlarge to the dev cluster, the entire team sees the $3,000/month price tag right there. It sparks the "do we really need that?" conversation instantly, preventing resource sprawl and keeping dev costs from going supernova.
The Safe & Informed Infrastructure Upgrade
You need to upgrade your database for better performance. Is moving from db.t3.medium to db.r5.large going to add $50 or $500 to the bill? Instead of guessing or wasting time modeling, your upgrade PR comes with a CloudBurn report showing the exact cost delta. This lets you make data-driven decisions and get approval without the financial ambiguity.
Enforcing FinOps Culture from the Ground Up
Trying to get engineers to care about cloud costs is tough without the right tools. CloudBurn bakes cost visibility directly into the developer's natural habitat—the PR. It makes cost accountability a standard part of the review checklist, right alongside linting and unit tests. This builds a culture of cost-aware engineering without the annoying nagging.
Preventing Production Bill Shock from Code Reviews
A junior engineer submits a change that adds an auto-scaling group. The code looks fine, but the CloudBurn report reveals it's configured to scale out to 50 massive instances under minimal load. The team catches this $15k/month risk in the review, comments on it, and adjusts the scaling policy. Crisis averted, bill protected, hero status achieved.
OpenMark AI
Pre-Launch Model Selection
You're about to bake an LLM into your app's new support chatbot. Do you go with GPT-4o, Claude 3.5 Sonnet, or a fine-tuned Llama? Instead of debating in Slack, create a benchmark with real user query examples. Run it. In minutes, you'll have data on which model understands your domain best, responds fastest, and keeps your API bill from being absolutely unhinged.
Validating Cost-Efficiency for a Workflow
Your data extraction pipeline uses an expensive top-tier model for every single document. Is that overkill? Use OpenMark to test your extraction prompts against cheaper, smaller models. You might find one that's just as accurate for simple forms, letting you save the big guns for only the complex cases and slashing your monthly costs dramatically.
Checking Output Consistency for Agents
Building a multi-agent system? You need to know if your "reasoning" agent is consistently logical, not just occasionally brilliant. Benchmark the same reasoning task 20 times. OpenMark's variance charts will show you if the agent's output is stable or all over the place, preventing a production nightmare where your agent randomly decides 2+2=5.
Comparing New Model Releases
A new model drops every Tuesday. Does it live up to the marketing for your tasks? Don't just read the blog post. Quickly clone an existing benchmark task in OpenMark, add the new hotness to the lineup, and run a head-to-head. See if it's actually worth switching your integration over to, based on your own real-world criteria.
Overview
About CloudBurn
Alright, let's talk about the cloud bill monster that's been giving your team nightmares. You know the drill: you merge a PR, your Terraform or AWS CDK stack does its thing, and you're feeling like a DevOps wizard. Then the end of the month hits, and BAM! Your AWS bill looks like it got hit by a freight train. Where did that extra $5K come from? Was it the new RDS instance? The accidentally public S3 bucket? It's a mystery that ruins your day and your budget. CloudBurn is here to be your financial bodyguard. It's the tool that slaps a price tag on your infrastructure code before it ever touches production. By integrating directly into your GitHub pull requests, it gives you and your team a real-time, line-by-line cost estimate of every change. Think of it as a crystal ball for your cloud spend, letting you catch those "oopsie" $10,000 configurations while they're still just code in a review. No more spreadsheet sorcery or post-deployment panic attacks. CloudBurn makes cost awareness a natural part of the dev workflow, so you can build with confidence and keep your finance team from having a meltdown.
About OpenMark AI
Alright, let's cut through the AI hype. You're building something cool, you need a brainy LLM to power it, and you're staring down a list of 100+ models like it's a Netflix menu with nothing good. Which one actually works for your thing? Which won't cost an arm and a leg? And will it flake out on you after one good response? That's the chaos OpenMark AI fixes. It's your personal AI model testing arena. You just describe your task in plain English (or any language, really), hit go, and it runs that exact prompt against a ton of different models—GPTs, Claude, Gemini, open-source stuff, you name it—all at once. No juggling a million API keys, no coding a bespoke testing suite. You get back a side-by-side breakdown of who's the real MVP, based on actual cost per API call, speed, scored quality, and—this is the kicker—consistency across multiple runs. So you see if a model is reliably smart or just got lucky once. It's built for devs and product teams who are done guessing and need hard data before they ship. Think of it as due diligence for your AI feature, so you don't end up picking the flashy model that totally bombs on your specific use case.
Frequently Asked Questions
CloudBurn FAQ
How does CloudBurn actually work?
It's pretty slick! You install our GitHub App and add a simple GitHub Action to your repos. This action runs when a PR is opened, captures the output of your terraform plan or cdk diff, and sends it securely to CloudBurn. Our engine analyzes the resource changes, fetches the latest AWS prices, does the math, and then our bot posts the itemized cost report back as a comment on your PR. All in a matter of seconds.
Is my code or cloud credentials safe with CloudBurn?
Totally. We take security super seriously. CloudBurn is a verified GitHub App, which means it follows strict security protocols. We never ask for or store your AWS credentials. The setup and billing are 100% handled through GitHub. We only see the planned resource changes from your diff or plan output—not your actual live infrastructure or secrets.
What if my estimates are wrong? Are they guaranteed?
We provide estimates based on the official AWS public pricing API and standard assumptions (like 730 hours/month for running instances). They are incredibly accurate for On-Demand resources. However, they're estimates—actual bills can be affected by real usage, discounts (like Savings Plans), or data transfer fees we can't predict from a config file. Think of it as the manufacturer's sticker price; it tells you the base cost before you drive it off the lot.
Can I use CloudBurn for free?
Yes! We have a Community plan that's free forever for public repositories. For private repos, you can start with a 14-day free trial of our Pro features, which includes unlimited cost reports on private repos. After the trial, you can choose to subscribe to Pro or drop back to the free Community tier, which has limits but lets you keep using the core functionality. No credit card is needed to start the trial.
OpenMark AI FAQ
Do I need my own API keys to use OpenMark?
Nope, that's the whole vibe! You use OpenMark credits. We handle all the API calls to the different model providers (OpenAI, Anthropic, Google, etc.) on our backend. You just describe your task, pick models from our catalog, and run the benchmark. No key management, no separate bills, no setup friction.
How is this different from reading benchmark leaderboards?
Those public leaderboards test models on generic tasks like trivia or math. OpenMark is for your specific, unique task. It's the difference between reading a car's top speed and actually test-driving it on your commute route. You get results based on your actual prompts, your data, and your definition of "good."
What kind of tasks can I benchmark?
Pretty much anything you'd use an LLM for! Common ones are classification, translation, data extraction, Q&A, summarization, creative writing, code generation, and testing RAG pipelines. If you can describe it, you can probably benchmark it. The platform is built for real-world, task-level testing.
How does the scoring and "variance" thing work?
When you run a benchmark, we execute your prompt multiple times for each model (configurable). We then score each output based on your task's goal. The results show you the average score, but more importantly, they show the spread—like a distribution chart. A tight cluster means the model is consistent. A wide spread means it's unpredictable, which is a huge red flag for production use.
Alternatives
CloudBurn Alternatives
Alright, so you're vibing with the whole "dodge the AWS bill shock" concept that CloudBurn is serving up. It's a total lifesaver for devs using Terraform or AWS CDK, basically acting as a financial bodyguard for your pull requests. It lives in that sweet spot of FinOps and DevTools, automating cost estimates right in your GitHub workflow so you don't deploy a money pit. But hey, maybe you're scoping out the scene. People peek at alternatives for all sorts of reasons—maybe the pricing structure doesn't fit your squad's size, you need support for a different cloud provider, or your CI/CD setup is built somewhere other than GitHub. It's all about finding the right fit for your stack and your budget. When you're on the hunt, you gotta weigh what matters most to you. Think about the depth of the cost breakdowns, how smoothly it plugs into your existing tools, and whether it gives you real-time pricing or just ballpark guesses. The goal is to keep those nasty billing surprises in the rearview, no matter which tool you roll with.
OpenMark AI Alternatives
So you're checking out OpenMark AI, the slick web app that lets you pit a hundred-plus LLMs against your specific task to see who's actually worth the API call. It's a dev tool built for the crucial pre-launch hustle, giving you the real tea on cost, speed, quality, and consistency before you commit code. People scope out alternatives for all the usual reasons. Maybe the pricing model doesn't vibe with your current workflow, or you need a feature that's still on the roadmap. Sometimes you just prefer a different interface or need it to play nicer with your existing tech stack. When you're shopping around, keep your eyes on the prize. You want something that gives you actual, unfiltered results from real API calls, not marketing fluff. The whole point is to nail down the best bang-for-your-buck model for your exact use case, so prioritize tools that deliver transparent, actionable data on performance and stability.