Agenta
Agenta is your go-to platform for building reliable LLM apps with seamless collaboration and smart experimentation.
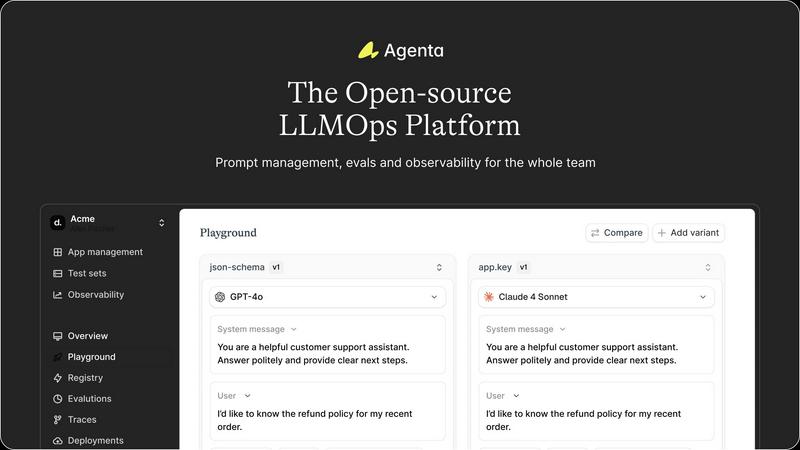
About Agenta
Alright, let’s spill the tea on Agenta. This open-source LLMOps sidekick is here to rescue you from the wild, wild west of AI app development. You know how it goes: prompts getting lost in the abyss of Slack DMs, PMs throwing together half-baked ideas in Google Sheets, and developers just sending their code into the production void without a second thought. It's a chaotic scene! Enter Agenta, your new best friend in the world of AI. This platform unites developers, product managers, and domain experts in a collaborative fiesta, all while keeping the chaos at bay. Think of it as your mission control, where you can experiment with prompts, run automated evaluations, and gain full visibility into what's happening in production. No more guesswork or random AI hallucinations ruining your features. Agenta transforms the unpredictable nature of LLM development into a structured, evidence-driven process, ensuring everyone’s on the same page. It’s the ultimate way to ship reliable LLM applications faster and with confidence.
Features of Agenta
Centralized Prompt Management
Say goodbye to the scattered mess of prompts across Slack and Google Sheets. Agenta centralizes everything in one platform, so you can easily track and manage your prompts without losing your mind.
Automated Evaluations
Forget about guesswork! With Agenta, you can set up a systematic process for running experiments and tracking results. This feature ensures that every change is validated, so you know what's working and what’s just a wild guess.
Full Observability
Debugging in AI can feel like a shot in the dark, but with Agenta, you get complete traceability for every request. This means you can pinpoint exact failure points and understand where things might have gone off the rails.
Collaborative Workspace
Agenta brings together product managers, developers, and domain experts into one cohesive workflow. This feature allows for real-time collaboration, where everyone can experiment, compare, and debug prompts without stepping on each other's toes.
Use Cases of Agenta
Streamlined Development Process
Agenta is perfect for teams looking to streamline their LLM development process. By centralizing prompts and evaluations, teams can iterate quickly and confidently, reducing the time it takes to bring applications to market.
Enhanced Collaboration
Whether you’re a developer, a PM, or a domain expert, Agenta enables you to collaborate seamlessly. This means fewer silos, more communication, and a unified approach to tackling AI challenges.
Data-Driven Decision Making
With Agenta’s automated evaluations, teams can make data-driven decisions rather than relying on gut feelings. This leads to improved performance and a more reliable AI application.
Efficient Debugging
When errors crop up, you can use Agenta to trace requests back to their source. This feature allows teams to annotate issues and quickly turn them into tests, making the debugging process faster and more efficient.
Frequently Asked Questions
What is Agenta?
Agenta is an open-source LLMOps platform designed to streamline the development of AI applications. It provides tools for prompt management, automated evaluations, and full observability, making it easier for teams to collaborate and build reliable LLM apps.
Who can benefit from using Agenta?
Agenta is tailored for AI teams, including developers, product managers, and domain experts. Anyone involved in the LLM development process will find value in Agenta's collaborative features and structured workflows.
How does Agenta improve collaboration?
By centralizing prompts and evaluations, Agenta breaks down silos between team members. This allows for real-time collaboration, enabling everyone to contribute to the development process without confusion or miscommunication.
Can Agenta integrate with existing tools?
Absolutely! Agenta is designed to seamlessly integrate with your existing tech stack, including frameworks like LangChain and LlamaIndex. This makes it easy to incorporate Agenta into your current workflow without a hitch.
Explore more in this category:
Similar to Agenta
HypeShare
Secure file transfer platform for sending large files fast — no signup required, end-to-end encryption, up to 10GB free.
JustLaunched
The launch platform for indie makers — schedule your launch, get in front of buyers, and blast across directories.